

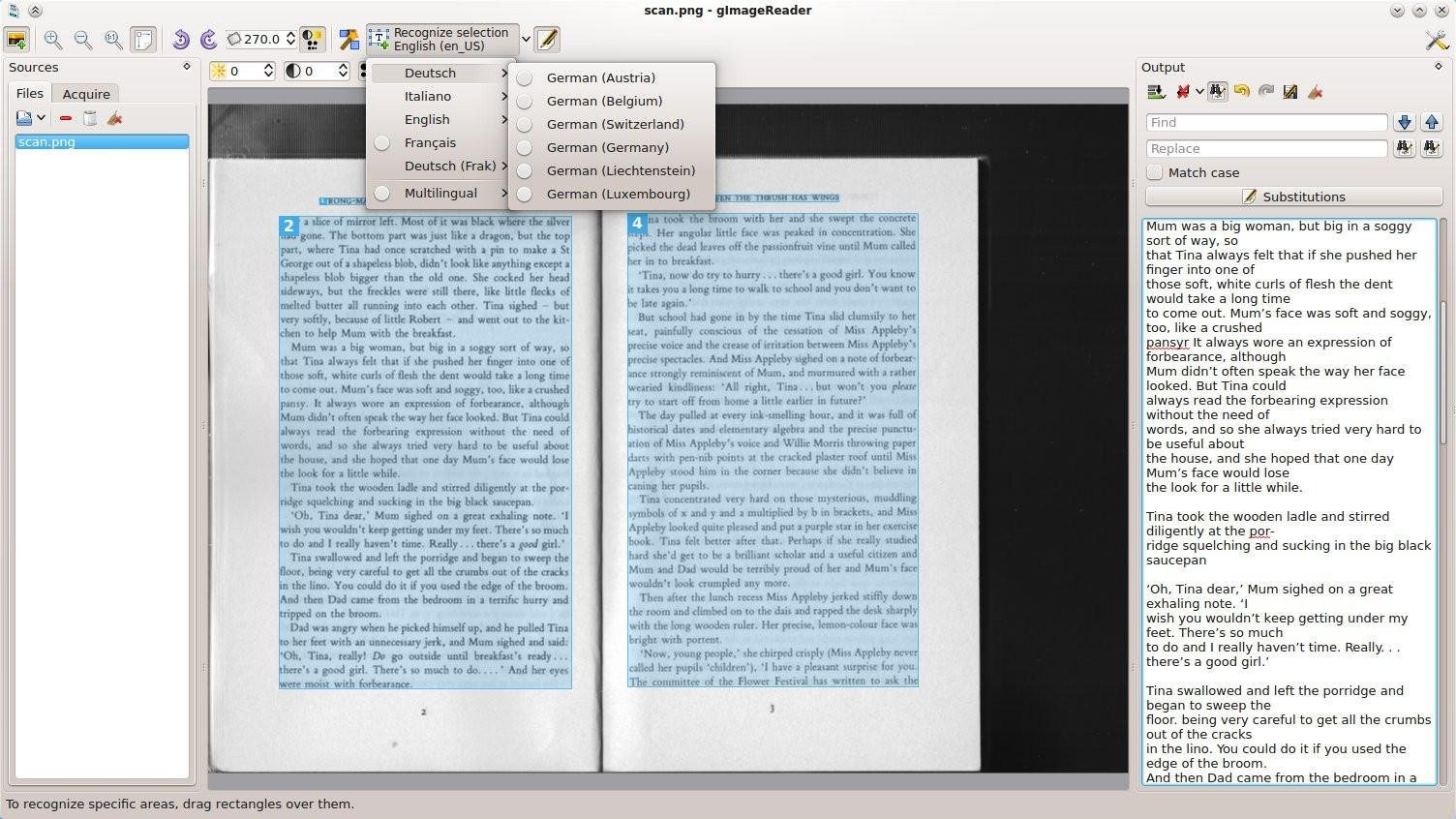
GImageReader is a simple front end for the Tesseract OCR engine.
The program makes it easy to extract text from images (either files, or pasted from the clipboard) or PDF documents. It can also import an image from your scanner, or - if everything else fails - take a screenshot.
Click "Autodetect layout" and gImageReader then tries to detect all the text regions within the source. You can tidy this up by deleting or reordering regions as you like. Alternatively, you might select an individual block of text just by clicking and dragging with the mouse.
If the task is a simple one, you could just right-click a region and select "Recognise to clipboard". GImageReader grabs whatever text it can from the image and copies it to the clipboard, ready for immediate reuse elsewhere.
Longer blocks can be sent to an "Output" pane for extremely basic editing: stripping line breaks, running search and replace tasks, or just manually cleaning up the text, before saving it as a TXT file.
Verdict:
GImageReader's interface is a little strange in places, but once you've figured it out it's easy enough to use, and Tesseract can be very accurate (although as with all OCR engines, it all depends on your source).
Your Comments & Opinion
Clean up your scanned documents with this easy-to-use tool
Grab text from images, videos and more
Use OCR to capture small amounts of text, saving the results to the clipboard
Scan documents to create editable PDFs with your mobile
Read, write and edit metadata in more than 130 file types with this command line tool
Read, write and edit metadata in more than 130 file types with this command line tool
Read, write and edit metadata in more than 130 file types with this command line tool
Automatically adjust your monitor settings to reduce eye strain
A powerful tool for detecting, benchmarking and monitoring your PCs hardware